[tabs title=”.“]
[tab title=”INTRO” active=”true”]
PREMESSA
In questa sede non si vuole proporre verità assolute, non credo ve ne siano, solo elementi su cui poter ragionare per arrivare a trarre delle proprie personali, anche se magari momentanee, conclusioni. E non si desidera nemmeno riproporre quanto già scritto in molti altri portali più o meno autorevoli sul mondo vocale, o meglio, si intende farlo in maniera differente, non enunciando postulati e tesi, ma lanciando ipotesi su cui poter discutere.
Probabilmente sarete a conoscenza del concetto di risonanza.
Ho notato che tale concetto rivolto all’emissione vocale non è sempre chiaro nella didattica di certi insegnanti di canto – e loro allievi di conseguenza. Stiamo parlando di uno strumento duttilissimo e dalle infinite possibilità, la voce, del quale possediamo un controllo spesso inconsapevole e sommario, anche per il fatto che non ne conosciamo bene la struttura.
Ora, un aspetto che credo tutti si possa condividere è questo, postulato appartenente a numerose tecniche vocali:
ad una precisa conoscenza fisiologica dell’apparato fonatorio
devo abbinare un database mentale di schematizzazioni figurative e propriocettive
Secondo me la questione è molto semplice (non la sua risoluzione); come potrei spiegare ad un non-udente la mia sensazione di suono? Probabilmente potrei cominciare con una spiegazione del concetto e sensazione di vibrazione.
Aiutandomi con esempi pratici e tattili, la sua mano sulla sua laringe durante le fonazione, ed esempi figurativi ed acustici quali fontanelle, cucchiai, spilli, fori sulla nuca o sotto al naso e quant’altro per fargli comprendere sensazioni riconducibili a focalizzazione, punta, maschera, cavità, colore, corpo, nasalizzazione, indietro, avanti, …, tutti termini che non amo particolarmente in questo ambito, data la loro oggettività praticamente inesistente, ma evidentemente utili strumenti allo scopo.
In effetti è quello che fa anche l’insegnante di canto con l’allievo alle prime armi, in questo caso non-udente nel senso di non-abituato-ad-ascoltarsi e ancora ignaro e inconsapevole di come sia strutturato fisiologicamente il proprio strumento.
I bassi, baritoni, tenori e contralti risultano essere più timbrati rispetto alle voci femminili acute;
ciò si può dedurre analizzando il suono vocale di una soprano, la cui formante alta di canto (o rinforzo formantico, o extra formante) risulta di bassa intensità.
La sensazione di suono brillante (che non è sinonimo di timbrato) tipico dei soprani è infatti determinato più che dalla scarsa rilevanza della formante alta di canto quanto dalla maggiore intensità rispetto alle altre voci delle prime componenti armoniche (ricordiamoci che la F0, frequenza fondamentale corrisponde al 1° componente armonico) e quindi della 1° formante.
In alcuni casi il 1° armonico coincide con la 1° formante, data la sua elevata intensità.
Ma come si può ottenere questa sensazione di brillantezza sopranile? Concettualmente è banale, dato che l’ampiezza della 1° formante F1 è in relazione con l’ampiezza della cavità orale, quindi
aumentando negli acuti l’apertura della bocca
Da ciò si evince che nelle voci maschili o di contralto noi percepiamo soprattutto l’intensità della formante di canto, mentre nelle voci femminili acute la frequenza fondamentale potenziata dalla sovrapposizione della prima formante.
Non solo, il tutto è condito dal fatto che oltre ai parametri quali intensità e frequenza vi è pure l’influenza della vocale che si sta emettendo, la quale influenza la tensione tra muscolo cricotiroideo e tiroaritenoideo.
Divaghiamo un attimo:
- salendo verso gli acuti senza coprire il suono si giunge prima o poi alla rottura, nonchè ad enorme stress muscolare
nella vocalità pop o belting, voce piena e spinta, il tempo di contatto tra le corde vocali si allunga, determinando la formazione di armoniche fino ai 5000 Hz con conseguente emissione graffiata, spinta, forzata, strìdula, compressa, … (ipercinesia fonatoria) con corrispondente perdita della caratteristica di copertura e rotondità del suono lirico.
Queste appena citate sono modalità di emissione non corrette dal punto di vista dell’igiene vocale.
Ho ritenuto questa premessa necessaria e doverosa.
[/tab]
[tab title=”SPETTROGRAFIA”]
LINGUISTICA
FONETICA : FONI = FONOLOGIA : FONEMI

ANALISI AUDIO VOCALE
Tecnica di analisi e interpretazione:
FFT Fast Fourier Transform: trasformata veloce di Fourier
versione ottimizzata della
DFT Discrete Fourier Transform: trasformata discreta di Fourier
FFT => scomposizione di un segnale in una serie di suoni sinusoidali ciascuno con propria frequenza, ampiezza e fase
Nel nostro caso un suono vocale risulterà perciò come somma algebrica di una serie di componenti sinusoidali
Tra le varie rappresentazioni grafico/matematiche del segnale vocale, le più efficaci sono:
SONAGRAMMA
SONAGRAM – SONOGRAM

In ascissa abbiamo il tempo, in ordinata la frequenza, e le linee orizzontali rappresentano le componenti armoniche. In realtà, in questo tipo di rappresentazione bi-dimensionale interviene un terzo parametro, il colore, le cui differenti gradazioni sono in relazione con diverse intensità delle componenti armoniche. Ormai la maggior parte dei software di audio analisi offre dei colormap predefiniti e spesso anche editabili a piacimento.
SPETTROGRAMMA
POWER SPECTRUM – ANALISI DELLA FREQUENZA

In ascissa abbiamo la frequenza e in ordinata abbiamo l’intensità. I picchi verticali rappresentano le componenti armoniche. Nell’immagine abbiamo uno spaccato istantaneo di un evento sonoro in un momento X del suo svolgimento acustico. Notiamo a sinistra alcune componenti armoniche con una certa intensità, destinata a scemare in quelle successive.

Nell’immagine sopra abbiamo la rappresentazione di 1 secondo di rumore; nella parte superiore abbiamo la forma d’onda, in quella inferiore un’immagine confusionale, il suo sonogramma.

Qui abbiamo la medesima forma d’onda con “zoom in” a 12 millisecondi; l’immagine risulta ancora complessivamente irregolare.

Cambiamo segnale audio, qui abbiamo una forma d’onda a dente di sega, 1 secondo a 1500 Hertz (Hz o CPS, cicli per secondo); ciò che notiamo subito è la forma d’onda graficamente compressa – 1500 cicli in pochi centimetri – rappresentata da una banda blu uniforme. Zoomando l’immagine

possiamo notare distintamente i cicli, creste e gole/avvallamenti (cosa sono? guarda sotto), puoi contarne 15 in 10 millisecondi (clicca sull’immagine sopra per ingrandire), infatti 1500 Hz : 1 sec = 15 Hz : 10 msec; qui il sonogramma presenta una serie di bande orizzontali ben distinte, le componenti armoniche, parallele ed equidistanti l’una dall’altra.

Dato ciò possiamo capire che:
- un evento acustico che noi definiamo rumore generalmente non è provvisto di frequenza chiaramente distinguibile, il suo sonogramma e forma d’onda risultano irregolari, il suono inarmonico
- la frequenza (Hz) viene calcolata in base al numero di ripetizioni delle creste in 1 secondo
- se un segnale è periodico (ripetizione regolare delle creste), probabilmente sarà costituito da componenti armoniche
- un segnale non periodico è caratterizzato da componenti inarmoniche
per cui:
- un segnale periodico produce la sensazione di altezza sonora (pitch)
- la percezione di altezza sonora non è così definita se la periodicità del segnale è meno regolare
- le componenti armoniche sono tutte multipli interi della frequenza fondamentale F0 (h1 o 1° componente armonica)
Aspetto particolare nella serie degli armonici è la relazione tra gli intervalli di ottava; proviamo a considerare un segnale audio a 100 Hz, esso sarà costituito da:
h1 = 100 Hz
h2 = 200 Hz
h3 = 300 Hz
h4 = 400 Hz
e così via…
In questo caso la frequenza di ciascun componente armonico hn sarà un multiplo della frequenza fondamentale F0, ovvero hn = (h1)n oppure hn = (F0)n; il rapporto di ottava tra le componenti armoniche si basa sul rapporto 2:1 tra un armonico hn e un suo antecedente:
h1 = 100 Hz
h2 = 200 Hz
h4 = 400 Hz
h8 = 800 Hz
h16 = 1600 Hz
h32 = 3200 Hz
e via a seguire …
Altro esempio nell’immagine successiva:

E ancora, gli armonici in posizione pari sono multipli ottava di un rispettivo antecedente, il 2° è multiplo ottava del 1°, il 4° del 2°, il 6° del 3°, l’8° del 4°, il 10° del 5°, … (rapporto 2:1), mentre gli armonici dispari introducono una frequenza corrispondente a una nuova nota, non ancora apparsa nella serie.
Altra particolarità; con diapason a 440 Hz consideriamo alcuni intervalli, ad esempio di 5°, tralasciando i decimali e approssimando:

mentre la differenza in Hz tra le due frequenze che costituiscono ciascun intervallo varia nei tre esempi, notiamo come il loro rapporto rimanga invece costante; da ciò si evince che per calcolare/confrontare gli intervalli il nostro sistema di codifica della percezione acustica considera il
rapporto
tra le frequenze, non le frequenze a sè stanti. Così noi percepiamo sempre lo stesso intervallo solo se il rapporto tra le frequenze è costante, in questo caso 3:2.
.
Nei prossimi due video alcuni cenni esplicativi sull’argomento:
[one_half]
[/tab]
[tab title=”RISONANZA”]
Affinchè uno strumento musicale possa svolgere la sua funzione, e cioè quella produrre uno o più suoni, devono coesistere due elementi indispensabili:
elemento vibrante – la fonte dell’energia sonora
uno o più risuonatori – le cavità che amplificano e modellano l’energia sonora
Per alcuni strumenti è previsto un terzo elemento:
adattatore di impedenza – (l’impedenza acustica è un valore che determina la resistenza di un fluido, aria, acqua, …, alla propagazione delle onde sonore) solitamente un elemento parte integrante dello strumento che trasferisce l’energia meccanica tra varie parti dello strumento stesso o tra lo strumento e il mezzo conduttore, generalmente l’aria che lo circonda
Come esempio consideriamo tre strumenti tradizionali:
il flauto – prevede come elemento vibrante l’aria, e come risuonatore la canna con i fori
la tromba – prevede come elemento vibrante le labbra dell’esecutore, come risuonatore la canna con i pistoni e come adattatore d’impedenza la campana, la quale adatta l’impedenza della canna a quella dell’aria circostante allargandosi gradualmente
il violino – prevede come elemento vibrante le corde, come risuonatore la cassa armonica, e come adattatore di impedenza il ponticello (in realtà anche l’anima e il corpo stesso del violino, ma non complichiamo le cose) il quale permette il trasferimento dell’energia meccanica prodotta dalle corde alla cassa armonica.
Potremmo affermare che la risonanza è quel processo mediante il quale un sistema può assorbire energia da un elemento vibrante solo in una determinata banda frequenziale corrispondente alle frequenze proprie:

- risonanza a 1500 Hz

La risonanza vocale corrisponde a quel processo per cui il debole effetto acustico determinato dalla vibrazione delle pieghe vocali, attraverso il passaggio nel Vocal Tract, viene modellato ed amplificato determinando il timbro vocale. Praticamente il tratto vocale, il risuonatore (o meglio l’insieme dei risuonatori), amplifica l’energia prodotta dalle corde vocali, la fonte, in certe bande frequenziali corrispondenti alle proprie frequenze di risonanza, smorzando le componenti armoniche estranee o distanti:

- risuonatori vocal tract, F1, F2 e F3

Come si vede nella figura sopra, ho simulato l’effetto di tre cavità di risonanza del tratto vocale, ciascuna con una propria frequenza di risonanza, 500, 1500 e 2500 Hz, come previste in un tratto vocale maschile di umano adulto (lunghezza media circa 17 cm.); come si nota nella sezione di OUTPUT della figura le componenti armoniche coincidenti con le frequenze di risonanza delle cavità sono di intensità maggiore rispetto alle componenti vicine, che anzi vengono smorzate; da qui possiamo quindi comprendere il significato di formante vocale (il quale in verità non si riduce a questa semplice definizione, ma approfondiremo in una prossima pagina):
le formanti vocali rappresentano le risonanze delle cavità del tratto vocale,
di frequenza variabile in relazione a struttura, forma
e dimensione delle cavità medesime
Parliamo di rinforzi armonici, di conseguenza formantici, dovuti alla configurazione mobile della cavità faringea, della cavità orale e della cavità nasale (la quale merita un capitolo a parte) determinata da diverse posizioni assunte da laringe, lingua, velo palatino, labbra e mandibola (o mascellare inferiore).
Ken Stevens, considerato uno dei massimi esperti di fonetica acustica e direttore dello Speech Communication Group presso il Massachusetts Institute of Technology, nel 1962 produce con l’aiuto del collega svedese Ohman questo filmato presso il Wenner-Gren Research Laboratory di Stoccolma, grazie al quale si riescono a notare abbastanza nitidamente le variazioni del tratto vocale in relazione a vari fonemi e alle due frasi finali Why did Ken set the soggy net on top of his deck? I have put blood on her two clean yellow shoes.
[sz-video url=”http://youtu.be/DcNMCB-Gsn8″ /]
Il filmato originale – alcune fonti discordano sul fatto che il soggetto fosse lo stesso Stevens o uno speaker canadese – è stato descritto ampiamente da J.S. Perkell nel suo Physiology of speech production: results and implications of a quantitative cineradiographic study del 1969. Per chi fosse interessato lo si può acquistare facilmente in rete, in ogni caso a questo link si può anche leggere qualche pagina introduttiva.
Gli stessi Stevens e Ohman ne parlano a pagina 15 di questo pdf.
E’ tutto un gioco di equilibrio.
Quindi l’onda sonora prodotta dalle pieghe vocali, man mano che proseguirà il suo percorso attraverso il VT e le cavità di risonanza, risulterà composto da armonici di differente intensità, dando luogo quindi a precise distribuzioni formantiche.
Ora bisogna fare chiarezza:
- le cavità di risonanza contengono aria
- l’aria, se investita da un’onda sonora, vibra
- a seconda della conformazione delle cavità di risonanza in quel preciso istante, il suono subirà il rinforzo di alcune armoniche piuttosto che altre, determinando definite zone formantiche
Alcune precisazioni:
ciò che funge da risuonatore non è la cavità di risonanza, ma l’aria in essa contenuta.
In questo bel filmato, Trevor Cox della University of Salford ci spiega in modo curioso il rapporto tra corpo vibrante e risuonatore seguendo il modello source-filter (ne accenneremo più avanti) utilizzando il classico palloncino/cuscinetto a pernacchia:
[sz-video url=”http://youtu.be/PVGk85rHjfE” /]
L’elasticità, la consistenza e la densità del materiale che costituisce l’involucro-contenitore della cavità determinano semplicemente in che modo l’aria verrà sollecitata; basti pensare alla differente qualità timbrica tra uno Stradivari e un violino cinese. In generale una parete molto elastica attenuerà l’energia sonora, al contrario una parete rigida l’amplificherà.
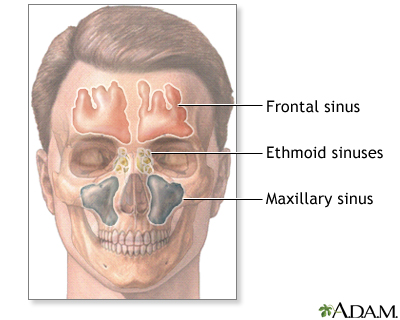
Vi sono ancora oggi idee differenti riguardo al ruolo dei seni paranasali nella produzione vocale; mentre secondo molti insegnanti di canto sarebbero di fondamentale importanza ai fini qualitativi del timbro vocale, secondo la foniatria non prenderebbero parte al processo di risonanza in quanto l’aria in essi contenuta non potrebbe essere sollecitata da alcuna energia sonora, non potendo quindi risuonare.
Se fosse vera la seconda ipotesi, come credo, quale significato assumerebbero i concetti di suono in maschera o voce di testa tanto cari ai maestri di canto tradizionali? Ne deduco che siano solo sensazioni vibratorie musco-scheletriche (come la voce di petto) e in quanto tali inutili nella formazione strutturale del timbro vocale; queste sensazioni fungono piuttosto da cartina di tornasole, nel senso che l’avvertire, il percepire la sensazione di suono in maschera conferma un efficiente ed efficace utilizzo delle cavità di risonanza del tratto vocale, le quali trasmettono la loro sollecitazione sotto forma di micro vibrazioni al massiccio facciale.
|
|
|


La produzione e “costruzione” delle vocali avviene nel tratto vocale, spazio compreso tra la glottide e le labbra, e comunque non dovrebbe coinvolgere la cavità nasale, la quale produrrebbe delle antirisonanze – o controformanti – che indebolirebbero anche le componenti armoniche deputate alla determinazione del colore e alla qualità del timbro. Vediamo come sono strutturate la cavità nasali:
[sz-video url=”http://youtu.be/E_9Fi960LLw” /]
Spesso mi sono trovato a discutere sulla questione con vari insegnanti di canto operistico, e solo con qualcuno disposto a prendere in considerazione delle alternative al proprio credo. Ovviamente il problema non è di tipo comunicativo – al limite terminologico – quanto di eccessivo ancoraggio da parte loro a proprie convinzioni basate giustamente su sensazioni propriocettive, ma senza possedere l’elasticità mentale per poterle o volerle giustificare o comprenderne il significato in profondità. Negli ultimi tempi la situazione è mutata leggermente, alcuni insegnanti si aggiornano e si documentano, allargando il proprio interesse verso l’acustica e la foniatria.
Il suono generato dalle pieghe vocali (o corde vocali, CV) è simile ad un debole ronzio; dalla glottide, spazio tra le CV, alle cavità sopraglottiche, verrà trasformato dalla loro conformazione strutturale. Il tratto vocale funge da cassa di risonanza, mutevole nella forma e in grado di creare all’interno della sua struttura diverse zone/cavità che, in relazione alla propria forma e dimensione, determineranno un incremento di determinate componenti armoniche. Nel seguente video abbiamo una dimostrazione di ciò che si può ottenere acusticamente utilizzando un vocal tract artificiale; per maggiori dettagli consiglio vivamente di leggere questo pdf, nel quale Satoru Fujita e Kiyoshi Honda offrono anche un’esauriente spiegazione sull’effetto di anti-risonanza delle fosse piriformi, pyriform fossa, individuabili al minuto 6:20 del secondo video:
[sz-video url=”http://youtu.be/wR41CRbIjV4″ /]
[sz-video url=”http://youtu.be/yQR8OWfLnMU” /]
Ora, senza riassumere il percorso storico della ricerca sull’acustica vocale – sarebbe improponibile dato il numero elevatissimo di pedagogisti e ricercatori – andiamo indietro nel tempo e vediamo a grandi linee cosa si pensava su quanto detto, elencando solo qualche nome:
-
si ritiene che la scienza vocale nasca con Claudius Galenus (2° secolo D.C.), probabilmente il primo a considerare il ruolo del cervello come artefice primo dell’emissione vocale; riteneva anche che l’altezza di un suono vocale fosse in relazione alla lunghezza della trachea, comparando l’organo vocale a un flauto
-
nel 1280 il monaco e teorico Hieronymus de Moravia (origini sconosciute, sembra fosse vissuto a Parigi) propone una sorta di categorizzazione vocale in tre registri: vox pectoris, vox gutturis e vox capitis
-
il francese Denis Dodart (1634 – 1707) attribuisce alla glottide l’origine del suono vocale, con la teoria secondo cui l’altezza dei suoni deve essere in relazione con la tensione delle corde vocali
-
attorno al 1740 Antoine Ferrein conduce una serie di analisi su cadaveri animali e umani, stabilendo che l’altezza di un suono vocale è determinata dalla frequenza di vibrazione delle corde vocali
-
nel 1754 Jean-Baptiste Bérard, all’epoca rinomato insegnante di canto e haute-contre, pubblica L’art du chant, attraverso il quale porta l’attenzione verso l’importanza della respirazione e le diverse posizioni della gola all’atto della fonazione
-
nel 1761 lo svizzero Albrecht von Haller, nel suo trattato Elementa Physiologiae Corporis Humani scrive sull’importanza delle risonanze della cavità nasale e dei seni paranasali; egli asserisce anche che le vocali sono determinate dalle diverse posizioni assunte dalla mandibola e della lingua
-
verso il 1770 il tedesco Christian G. Kratzenstein, grazie anche alla suo lavoro con giovani pazienti affetti da mutismo, propone una tabella con le diverse posizioni di laringe, palato, mandibola, lingua e labbra per ciascuna vocale
-
nel 1791 l’ungherese Wolfgang von Kempelen costruisce una sorta di macchina parlante – in realtà produce delle consonanti – e una macchina per la produzione di vocali artificiali
-
nel 1848 il tedesco Johannes Moellercompie alcuni esperimenti soffiando aria attraverso laringi prelevate da cadaveri umani, concludendo che il suono proveniente dalla laringe non corrisponde a quello udibile nel parlato (o cantato) e dando così origine alla teoria sorgente-filtro (ripresa nel 1960 da Gunnar Fant); nelle sue analisi riesce a simulare il suono vocalico aggiungendo alle laringi in esame tubi di lunghezza pari a quella del tratto vocale
- Manuel Garcìa figlio (1805 – 1906), inventore nel 1855 del laringoscopio e ritenuto all’epoca il più illustre didatta vocale, rielabora alcune teorie del padre – maestro di canto e abile esecutore – e grazie anche al suo temporaneo impiego presso un ospedale militare durante il quale poté analizzare l’anatomia dell’organo vocale sui corpi dei soldati passati a miglior vita, pubblica il suo Traité complet de l’art du chant, attraverso il quale illustra l’anatomia e i meccanismi dell’apparato vocale, dalla respirazione costo-diaframmatica ai passaggi di registro; teorizza e dimostra l’efficacia del timbre sombre (copertura) contrapposto al timbre clair, caratterizzante il belcantismo italiano

-
negli stessi anni Karl Friedrich Salomon Liskovius, collega di Helmholtz, arriva alla stessa conclusione di J. Moeller, e cioè che una laringe non può produrre un timbro ricco-completo in assenza di risonanze sopra/sotto glottiche; Liskovius teorizza anche un’importante relazione: l’altezza di un evento sonoro è in relazione con il volume della cavità di risonanza, più la cavità è ampia e più la frequenza sarà grave e viceversa
- nella seconda metà del 19° secolo si contrappongono due teorie riguardo la produzione delle vocali, la Harmonic Theory, supportata da Helmholtz e Wheatstone e la Inharmonic Theory, supportata da Scripture, Willis e Hermann; la disputa nasce da questi due quesiti:
- quante e quali risonanze concorrono alla produzione delle vocali e quale sarebbe il loro rapporto con le cavità del tratto vocale?
- le frequenze di risonanza sono in relazione con l’eccitazione dei risuonatori determinata da successivi impulsi laringei?
In seguito saranno così riassunte dal fisico americano Harvey Fletcher:
Harmonic Theory
The vocal cords generate a complex wave having a fundamental and a large number of harmonics. The component frequencies are all exact multiples of the fundamental. …when these waves pass through the throat, the mouth, and the nasal cavities those frequencies near the resonant frequencies of these cavities are radiated into the air very much magnified, … These reinforced frequency regions determine the vowel quality.
ovvero, le corde vocali producono un suono complesso provvisto di componenti armoniche – e quindi di una frequenza fondamentale, il suono passa attraverso il tratto vocale, le frequenze più vicine alle frequenze di risonanza del tratto vocale vengono amplificate maggiormente rispetto ad altre, determinando la qualità vocalica
Inharmonic Theory
The vocal cords act only as an agent for exciting the transient frequencies which are characteristic of the vocal cavities. A puff of air from the glottis sets the air in these cavities into vibration. This vibration soon diminishes until it is started anew by a second puff. …the puffs do not necessarily follow each other periodically.
ovvero, la glottide produce soffi d’aria (impulsi) che, entrando nel tratto vocale, eccitano le onde sinusoidali corrispondenti alle frequenze di risonanza del tratto; l’eccitazione poi decresce rapidamente fino al momento in cui uno sbuffo successivo ricomincia il ciclo; gli sbuffi d’aria non necessariamente si susseguono con una frequenza che è uguale alla frequenza di risonanza del tratto e non consistono di parziali che hanno frequenze diverse
Entrambe le teorie saranno supportate fino al 1930 anche da cantanti e insegnanti di canto, in seguito la Inharmonic Theory verrà confutata.
-
nel 1878 il fisico tedesco M.J. Oertel utilizza uno stroboscopio per visualizzare le corde vocali durante la fonazione, consentendo una vista dettagliata della laringe nelle diverse posizioni “al rallentatore”.
-
nel 1862 Hermann von Helmholtz scrive Die Lehre von den Tonempfindungen als physiologische Grundlage für die Theorieder Musik (tradotto da A.J. Ellis nel 1885 – On the sensation of tone as a physical basis for the theory of music), testo sui suoi studi, dai quali deriva la teoria degli armonici. Per i suoi esperimenti sulle risonanze utilizza dei risuonatori – sfere di vetro prima, di ottone in seguito – di varie dimensioni e munite di due aperture opposte, una larga a collo corto in comunicazione con l’esterno e una stretta a collo lungo in comunicazione con il condotto uditivo; ciascun risuonatore assorbe energia acustica in relazione alla forma/dimensione e al diametro dell’apertura a collo corto, rendendo quindi possibile determinare se all’interno di un evento acustico sia presente una certa frequenza, ovvero: l’orecchio può distinguere la frequenza del risuonatore, la quale viene rinforzata per risonanza, tra quelle componenti il suono stesso. In verità Helmholtz riprende e chiarisce le considerazioni che i colleghi Karl Liskovius (relazione frequenza/volume del risuonatore) e Karl Sondhaus(s) (relazione frequenza/area apertura del risuonatore) teorizzano qualche anno prima. Secondo Helmholtz le cavità del tratto vocale agiscono da risuonatori semplici; le vocali sarebbero prodotte da una o al massimo due frequenze di risonanza

phys.cwru.edu
-
nel 1879 lo scienziato Alexander Graham Bell, conosciuto ai più per la disputa con Meucci riguardo la paternità dell’invenzione del telefono, sperimentando varie sonorità vocali e tastandosi manualmente gola e guance, asserisce di aver verificato l’esistenza di due frequenze (di risonanza?) per ciascuna vocale in relazione alle diverse dimensioni che possono assumere le cavità del tratto vocale, ma non fornisce alcun dettaglio o valore numerico. Dopo il primo conflitto mondiale molti ingegneri dei laboratori di ricerca del Bell Telephone System deviano la propria ricerca nell’ambito dello speech and hearing; nel 1922 tale Stewart costruisce un synth costituito da un cicalino e da due circuiti di risonanza in parallelo – due e non di più, secondo la tesi (di Helmholtz) per la quale nella cavità orale si sarebbero potuti verificare solamente uno o al massimo due modi di vibrazione – in grado si simulare tutte le vocali variando il tuning dei circuiti stessi; un altro ingegnere, Crandall, grazie all’utilizzo di circuiti ottici, stabilisce che sia le vocali posteriori sia anteriori sono originate da più modi di vibrazione, e quindi da più zone di risonanza; per finire con Steinberg, Lewis e Russel (grazie ad analisi ai raggi X ) che tra il 1930 e il 1935 arrivano a mettere in discussione la tesi helmholtziana riscontrando fino a cinque zone di risonanza del tratto vocale, ma senza indicarne la localizzazione
-
il celebre tenore Jean de Reszke (1850–1925), di origine polacca ma naturalizzato francese, considerato in Francia un valente didatta e pedagogista vocale tanto da essere considerato quasi un guru, è un convinto assertore del cantare in maschera; in seguito alcuni suoi detrattori reputano le sue teorie responsabili del fatto che proprio la Francia non abbia mai prodotto valenti cantanti
-
nel 1902 il famoso soprano tedesco Lili Lehmann pubblica il suo trattato Meine Gesangskunst, nel quale propone una netta distinzione tra la funzionalità delle risonanze del cavo orale e delle cavità nasali in funzione dell’altezza del suono da produrre; è un testo molto interessante, lo potete leggere gratuitamente in lingua inglese a questa pagina
-
nel 1904 J. Fisher e J.F. Moeller utilizzano i raggi X, scoperti nel 1895, per analizzare le varie posizioni della laringe durante la fonazione a diverse altezze; E.A. Meyer nel 1910 e D. Jones nel 1932 estendono l’analisi alle posizioni della lingua, mettendo in discussione l’allora in uso grafico/diagramma delle vocali (vowel chart)
-
l’americano Edward Wheeler Scripture (1864-1945) è stato un fautore della Inharmonic Theory: la laringe non produrrebbe componenti armoniche ma una serie di impulsi (sbuffi), determinanti l’altezza del suono, i quali ecciterebbero l’aria contenuta nei risuonatori del tratto vocale dando origine al suono similarmente al suono prodotto soffiando in una bottiglia; Scripture accetta la convinzione di Helmholtz e Wheatstone per cui secondo il teorema di Fourier si possono individuare le componenti armoniche di un suono, ma ritiene ciò inapplicabile al suono vocale, tanto da preferire una formula di un altro matematico, Hermann, per dimostrare che gran parte dei calcoli utilizzati per scomporre il suono vocale mediante la trasformata di Fourier potrebbero essere analizzati ulteriormente per mostrare la presenza di componenti inarmoniche
-
nei primi anni del ‘900 il fisico americano Dayton Clarence Miller (1866 – 1941), inventore del Phonodeik – precursore dell’oscilloscopio, riesce a sintetizzare la parola papa utilizzando dieci canne d’organo di legno intonate sulle prime dieci componenti armoniche e andando a modificare l’intensità in uscita di ognuna di esse; Miller teorizza la possibilità che la vocale [a] possegga due risonanze – e non una come si pensava all’epoca – oggi identificabili con le prime due formanti F1 e F2
-
nel 1909 E.G. White, un adepto della Inharmonic Theory, nel suo Science and Singing propone una teoria secondo la quale la risonanza relativa allo sviluppo di componenti armoniche acute caratterizzanti la qualità del timbro vocale proverrebbe dai seni mascellari e frontali
-
nel 1949 l’americano William Vennard scrive il fantastico Singing: the mechanism and the technic, scaricabile gratuitamente qui
-
nel 1960 lo svedese Gunnar Fant, riprendendo le considerazioni di Johannes Moeller, illustra nel suo libro Acoustic theory of speech production la teoria sorgente-filtro, secondo la quale la fonte dell’energia acustica sarebbe la laringe, mentre il tratto vocale fungerebbe da filtro che determina la qualità del suono
-
negli anni ’70 un altro svedese, Johan Sundberg, analizza e formalizza la singer’s formant (e ne conia il termine), risonanza tipica delle voci a elevata portanza e operistiche, nel suo libro The Science of the Singing Voice; in realtà Sundberg non è l’unico a rilevare l’importanza delle componenti armoniche acute. Già nel 1934 (!) Wilmer T. Bartholomew sostiene che la brillantezza vocale di un cantante d’opera sia da attribuire alla presenza di componenti armoniche particolarmente intense attorno ai 3.000 Hertz, tanto che nel suo articolo A physical definition of “good voice-quality” in the male voice scrive “… una formante alta, solitamente situante per voci maschili tra circa 2400 e 3200 cicli. … In generale, migliore è la voce, o più presente il suono, e più prominente diventa questa formante”. Negli anni ’70 T.F. Cleveland riscontra che, a parità di vocale emessa, la frequenza delle formanti muta in modo direttamente proporzionale al tipo di voce, ovvero diminuirebbe leggermente nei bassi e aumenterebbe leggermente nelle voci tenorili; all’inizio del millennio attuale Cleveland riscontra la presenza di frequenze acute riconducibili all’extra formante anche nella vocalità dei cantanti di country music, ma semplificherà la questione parlando di speaker’s formant, quarta formante F4, (oggi shouter’s formant) situata tra i 3.000 e 3.800 Hertz.
-
Ingo Titze, fisico americano e coniatore del termine vocology, conduce una serie di ricerche sulle risonanze vocali e sul rapporto tra le prime due formanti
Ho citato solo alcuni ricercatori, tralasciando nomi anche altrettanto illustri, comunque quanto basta per avere un’idea del percorso sulla ricerca del significato di risonanza vocale, e quindi della formazione vocalica. Appare abbastanza chiaro come nel corso del tempo l’indagine abbia seguito due percorsi paralleli e nemmeno troppo distanti, speech e singing; altro aspetto particolare, la ricerca ha coinvolto in gran parte studiosi americani e svedesi, soprattutto negli ultimi decenni.
.
[/tab]
[tab title=”GLOTTIDE”]
L’elevata pressione sottoglottica può essere considerata veramente deleteria se associata ad emissione in registro modale (pieno) con tempo di contatto delle pieghe vocali superiore al 50% e posizione elevata della laringe.
Le pressioni sottoglottiche influenzano:
- la vibrazione delle CV per effetto Bernoulli
- il timbro vocale, che viene determinato sicuramente dal filtraggio del vocal tract, ma anche dalla modalità di vibrazione delle CV, regolata dalle pressioni sottoglottiche e dai muscoli laringei
- l’intensità
- la portanza
- indirettamente la F0 (frequenza fondamentale), controllata dai muscoli laringei, che aumentando o diminuendo la lunghezza e la tensione delle CV e quindi variando la superficie della glottide (spazio tra le CV) influiranno appunto sulla pressione sottostante
- l’emissione in falsetto, dove sembra che i muscoli cricotiroideo e tiroaritenoideo non siano più sufficienti a controllare la F0
- i tempi di contatto delle CV
-
la possibilità di emettere medesime frequenze con registri differenti
A questo punto risulta retoricamente evidente come il controllo della pressione sottoglottica sia fondamentale e necessario per la produzione vocale, e come esso sia in relazione al controllo diaframmatico. Infatti l’eccessiva e non controllata pressione sottoglottica dovuta ad uno scarso controllo diaframmatico può comportare un altissimo rischio patologico nonchè affaticamento vocale, del tipo
spingi giù e in fuori il diaframma
che può favorire l’essere calante ed un vibrato ampio ed eccessivo (in ogni caso innaturale), ma anche del tipo
spingi in dentro e verso l’alto il diaframma
che al contrario può comportare una presunta compensativa chiusura della gola, intonazione crescente e vibrato caprile (anch’esso innaturale).
Anche la percezione di suono in maschera sembra sia correlata alla pressione fonatoria. Secondo l’americano Ingo Titze tale sensazione vibratoria, perchè questo è e nulla di più, diviene acusticamente percepibile sia dall’emettitore sia dall’ascoltatore in quanto non vera risonanza (appunto), ma come diminuzione della pressione fonatoria determinante un’effettiva conversione dell’energia aerodinamica in energia acustica.
Sappiamo che l’energia aerodinamica viene trasformata in energia acustica nella laringe. Diviene VOCE solamente dopo un complesso sistema di filtraggio ad opera del vocal tract e successiva emissione attraverso le labbra.
La fonazione vera e propria avviene esclusivamente a livello della glottide e riguarda il segnale alla sua sorgente; tutto il resto, da fonazione diventa articolazione e risonanza.
All’atto della fonazione il segnale risultante dovrebbe essere di tipo
periodico complesso
Periodico in quanto ripete i suoi valori, la sua forma, ad intervalli uguali di tempo.
Complesso in quanto formato dalla somma algebrica di onde sinusoidali con rispettive frequenze e ampiezze.
In realtà il segnale è di tipo quasi periodico date le micro variazioni di intensità e frequenza a cui è fisiologicamente soggetto. Sarà quindi caratterizzato da una frequenza fondamentale F0 e da componenti definite armoniche in quanto con frequenza a multipli interi della F0. Quindi lo stesso segnale può divenire complesso aperiodico per irregolare vibrazione delle CV, con conseguente generazione di rumore; le componenti non saranno armoniche in quanto non più multipli della F0.
Vediamo ora la differenza tra segnale glottico, la sorgente, e la voce, dopo il vocal tract: ovviamente il primo avrà uno spettro più semplice per assenza di filtraggio da parte del tratto vocale, e sarà praticamente identico a prescindere dalle diverse vocali emesse – anche se con indagine EGG (elettroglottografia) si possono evidenziare minime variazioni – e le ampiezze delle componenti armoniche diminuiranno con l’aumentare della frequenza, dimostrando che il picco di energia si ottiene con frequenze basse:
|
nella parte alta della figura notiamo uno spettro sonoro di sawtooth che dovrebbe simulare lo spettro di un suono vocale glottico, in quanto abbastanza somiglianti;
|
 |
| nella parte centrale della figura possiamo vedere i picchi delle prime tre formanti, posti rispettivamente a 500, 1500 e 2500 Hz, come previsto mediamente per un tratto vocale umano di adulto (circa 17 centimetri), che andranno ad agire come banco di filtri e a strutturare timbricamente il suono vocale; | |
| nella parte bassa della figura abbiamo il risultato acustico, ovvero il suono glottico filtrato, che ovviamente varierà a seconda del tipo di vocale emessa e quindi delle mutazioni delle cavità di risonanza del tratto vocale. |
Un altro aspetto interessante del suono vocale alla sorgente è dato dalla differenza non perfettamente lineare in ampiezza della prima componente armonica in relazione alle seguenti; lo spettro, come già detto, risulta relativamente semplice, con riduzione progressiva dell’ampiezza delle componenti armoniche dalla 1° in poi di 12 dB per ogni raddoppio della frequenza, e non è poco. Quindi già la seconda componente armonica sarà a -12 dB, la quarta a -24 dB e così via.
Ecco a riguardo un interessante articolo da www.ncvs.org – National Center for Voice and Speech/Division of The Denver Center for the Performing Arts and a Center at The University of Iowa:
[…]
Spectral slope influences the timbre of the sound, just as waveform shape does, as described above. A spectral slope of around 6 dB/octave, the least severe slope in the graph, results in stronger high frequencies, which yield a more ‘brassy’ or strident sound. The middle slope depicted, 12 dB/octave, is that of a normal vocal quality. The most extreme slope shown, 18 dB/octave, would result in a more ‘fluty’ sound; it has stronger low frequencies, as compared to the higher ones, which rapidly drop off in strength.

La frequenza fondamentale F0 è determinata dall’attività di apertura-chiusura della glottide, ed è variabile mediamente in funzione di sesso ed età. Ecco qui sotto un elenco delle frequenze fondamentali (ovviamente in Hertz), dai primi anni di vita all’adolescenza, proposte da Wilson alla fine delgli anni ’70 nel suo Voice disorders in children:

Questi valori si riferiscono alle frequenze producibili esclusivamente alla sorgente, per cui a prescindere da ciò che si pronuncia di fatto, dato che il tatto vocale influenza solo ampiezza e fase delle componenti armoniche, mentre il segnale prodotto delle corde vocali può variare in frequenza e/o in ampiezza, e ciò può dipendere dalla pressione sottoglottica, nonchè dalla lunghezza, tensione e modalità di vibrazione delle stesse.
Alla nascita le corde vocali misurano circa 5 millimetri, per poi allungarsi fino ai 15/22 mm. nell’uomo e ai 12/17 mm. nella donna. Si può notare come nei primi anni non vi siano condiderevoli differenze; la posizione laringea e la massa cordale difatti sono molto simili tra i due sessi, così come la lunghezza delle pieghe vocali. Una cosiddetta voce bianca, ovvero voce di bambino/a che non ha ancora raggiunto la pubertà, non presenta infatti particolari differienziazioni acustiche tra maschio e femmina, presentando simili dimensioni del tratto vocale e delle corde vocali. Il termine bianca, un tempo utilizzato per la voce degli eunuchi, starebbe ad indicare la purezza e il candore giovanile.
Con l’età questi parametri varieranno determinando la struttura timbrica del suono vocale. Infatti abbiamo già osservato come la diversa conformazione assunta dal tratto vocale, a cui anche le diverse posizioni della laringe concorrono, determina appunto diverse frequenze di risonanza.
A tal fine ricordo l’esistenza dell’applicazione per windows VTDemo, di cui ho già parlato qui, mediante la quale possiamo analizzare gli effetti vocalici ottenuti andando a variare tutta una serie di modelli articolatori, compresi il basculamento della cartilagine cricoide (atteggiamento tipico del pianto) e la pressione sottoglottica.
[/tab]
[tab title=”F1 – F2″]
.

formante = concentrazione di energia in una banda frequenziale comprendente una o più componenti armoniche
Alcuni aspetti interessanti della struttura formantica:
– le prime due formanti contengono sufficienti informazioni affinchè il nostro sistema di audio-codifica identifichi e classifichi un timbro vocalico
– ciascuna delle 7 vocali della lingua italiana prevede almeno 5 formanti, situate in zone frequenziali ben precise
– la frequenza della prima formante F1 è in relazione con l’ampiezza dell’apertura della boccala
– frequenza della seconda formante F2 è determinata dalle diverse posizioni della lingua
Diamo ora un’occhiata a questa immagine:
sono raffigurate le frequenze delle prime due formanti di tutte e 7 le vocali, con relativo assetto del tratto vocale.
La cosa interessante è che per ogni vocale la posizione delle formanti non cambia pur variando la frequenza che si sta emettendo.
Ciò che fa la differenza è la diversa quantità di informazioni contenute in ciascuna formante; nella figura qui a destra si nota come emettendo la stessa vocale [a] su frequenze diverse si determinino identici formanti ciascuno con una quantità diversa di componenti armoniche. Ciò avviene in quanto aumentando la frequenza, il primo armonico si sposta visivamente verso destra, e così tutti gli armonici successivi, che sono suoi multipli interi.
Questo è anche uno dei motivi per cui facciamo più fatica a notare differenze timbriche tra due soprani piuttosto che tra due bassi.
Tornando alla figura di sinistra, Mauro Uberti fa notare una cosa molto interessante: il picco della prima formante aumenta di frequenza dalla [i] fino alla [a], per poi decrescere e tornare alla posizione di partenza dalla [a] alla [u].
Il motivo è semplice quanto affascinante: F1 (prima formante) è in relazione anche con l’ampiezza della cavità faringea (dietro la lingua per intenderci), che in effetti, osservando la figura, prima diminuisce e in seguito aumenta.
Idem dicasi per le posizioni di F2 che si posiziona attorno ai 2700 nella [i] (cavità buccale piccola) e man mano scende fino ai 700 Hz nella [u] (cavità buccale ampia).

- Georgia State University

In quest’altra immagine abbiamo una chiara visione spettrografica di F1 e F2 e loro variazioni per ciascuna vocale:

Per contro è interessante notare, come già menzionato, come al variare della frequenza di una medesima vocale i formanti cadano sempre nelle medesime bande frequenziali:

In pratica la posizione invariabile dei formanti mi garantisce il riconoscimento e l’identificazione timbrico-vocale a prescindere dall’altezza del suono emesso; infatti se campionassimo una qualsiasi frequenza vocale e poi con la nostra bella tastierina MIDI suonassimo una bella scala ascendente dalla nota più bassa alla più acuta, sentiremmo un timbro che da muggito si trasforma in vocina da polmoni pieni di elio.
Ciò perchè mutando il pitch cambia anche la distanza frequenziale tra i formanti. Questo è uno dei motivi per cui uno strumento campionato deve essere costituito da un campione per ogni singola nota: si campiona un do suonato da un pianoforte e si assegna al tasto do corrispondente, poi si suona un do#, si campiona e si assegna al tasto do#, e via dicendo.
Ecco un esempio del comportamento formantico umano, prima con [i], poi con [ò], e le zone formantiche rimangono invariate, per finire col terzo esempio, una [i] compressa e dilatata digitalmente in modo progressivo, e le zone formantiche seguono l’andamento (gli esempi partono al 7° sec.):
Graficamente vi è un modo molto semplice per coordinare l’azione dei primi due formanti F1 e F2 il cui rapporto determinerà le diverse vocali, ovvero si prende un piano cartesiano e sull’asse x si dispongono le frequenze di F1 e sull’asse y le frequenze di F2, in questa maniera:

ho cerchiato in rosso molto approssimativamente le coordinate dei primi due formanti, nel senso che ad esempio la vocale [è] emessa da voce liricamente ben impostata potrebbe risultare come F1=1400 Hz e F2=1500 Hz.
Da questo diagramma si evince come per trasformare la [u] in [i] sia sufficiente spostare la banda di F2 da 800 Hz verso i 2300 Hz, mentre F1 rimane ancorata ai 350 Hz.
Riflettendoci appare chiaro, infatti nel passaggio da una vocale all’altra il vocal tract assume forme diverse grazie ai movimenti di labbra, lingua, palato molle e spostamenti della laringe e della mandibola, venendosi a creare quindi al suo interno cavità più o meno ampie, la dimensione delle quali determina il rinforzo di certi gruppi di armonici (formanti) piuttosto che di altri.
F4, che contribuisce a quel rinforzo chiamato extra formante di canto di cui abbiamo già accennato e di cui c’è ancora molto da dire, aumenta la sua intensità grazie all’abbassamento verticale della laringe, non fino all’atteggiamento tipico dello sbadiglio ma a quello tipico del pianto.
.
[/tab]
[tab title=”SINGER FORMANT”]
.
Vi sono vari modi per definire una formante:
- concentrazione di energia acustica in una certa banda frequenziale
- picchi in uno spettro sonoro causati dalla risonanza acustica
Le prime 2 formanti, F1 e F2, con la loro variazione in ampiezza e in frequenza, determinano la varietà vocalica.
Ora potremmo porci due domande:
- come può il nostro sistema acustico discriminare chiaramente una voce operistica da una voce non impostata?
- come può essere che il più delle volte una voce operistica possa essere udibile anche al di sopra di un fortissimo orchestrale?
Gli studi di Johan Sundberg hanno portato alla scoperta di una particolare formante, l’EXTRA FORMANTE, in quanto sita costantemente in quella banda frequenziale che va da circa 2500 a circa 3500 Hz e, aspetto particolare, a prescindere dalla vocale emessa.
Aspetto particolare perchè sappiamo che ognuna delle 7 vocali della lingua italiana contiene una precisa disposizione formantica:
 © Mauro Uberti © Mauro Uberti |
|

Ovvero ogni vocale possiede una sua precisa struttura formantica variabile (vedi prima immagine), eppure l’extra formante si situerà sempre tra i 2500 e i 3500 Hz.
Da un articolo dello stesso Sundberg:
La formante del cantante è un picco che emerge nel profilo spettrale attorno ai 3 chilocicli, che si riscontra tipicamente nelle vocalizzazioni prodotte da cantanti lirici classici. Secondo una ricerca precedente, si tratta principalmente un fenomeno risonante prodotto dalla fusione (clustering) delle formanti 3, 4 e 5. Il suo livello, rispetto alla prima formante varia a seconda della vocale, l’intensità della vocale ed altri fattori. Viene qui esaminata la sua dipendenza dalle frequenze delle formanti delle vocali. Applicando la teoria acustica sulla produzione della voce, viene calcolata la differenza tra i livelli della prima e della terza formante per alcune vocali standard. Viene individuata la differenza fra i livelli osservati e quelli calcolati per voci diverse. Si è trovato che questa varia considerevolmente tra le vocali cantate dai cantanti professionisti e quelle cantate da principianti.
Acusticamente corrisponde a una specie di ronzio. Fisicamente si forma in quella zona del vocal tract compresa tra la glottide e l’epiglottide.
Ecco una dimostrazione: è sufficiente registrare col PC un segnale audio vocale di voce operistica di qualche secondo su frequenza X con vocale ad esempio [o], e poi, con software apposito, calcolare l’FFT (scomposizione del suono registrato nelle sue componenti armoniche).
analisi:
- a sin noto il picco della 1° form, (notare come la 2° componente armonica sia di intensità più che doppia rispetto alla 1° (F0);
- verso dx incontro la 2° form. che , trattandosi della vocale [o] si posizionerà sui 1000 Hz,
- poi attorno ai 2500/3000 hz noto una formante di ampiezza molto sigificativa, la nostra EXTRA Formante.

- con un filtro a reiezione di banda (lascia passare le frequenze che si trovano al di sotto e al di sopra di un intervallo, eliminando tutte quelle che sono comprese nell’intervallo stesso da me prestabilito), o ancor meglio con un equalizzatore grafico, comincio ad abbassare progressivamente il volume dell’extra formante
risultato:
- il segnale vocale risultante corrisponde ovviamente alla stessa nota-frequenza, ma da suono tipicamente lirico si è trasformato in suono dal timbro non impostato.

A questo punto se con un filtro passa banda (lascia passare inalterate tutte le frequenze il cui valore è entro un determinato intervallo eliminando quelle al di sopra e al di sotto della banda da me prestabilita) isolassi questo formante dal segnale originario, sentirei un bel ronzio, con una frequenza abbastanza identificabile e molto simile al frinire delle cicale.
Quindi questo ronzio determina la differenza tra la vocalità lirica e non. E non solo; dato che l’estensione di un’orchestra di stampo operistico arriva mediamente verso gli acuti attorno ai 2500 hz, sviluppando l’ampiezza di questo formante (2500/3500 hz) il cantante d’opera ha la possibilità finalmente di farsi udire, sviluppando così la sua portanza vocale.
Dal punto di vista fisiologico, tutto ciò è strettamente legato al concetto di copertura (registro secondario):
- abbassamento della laringe (pianto)
- abbassamento della mandibola
- abbassamento della base linguale
- elevazione del velo palatino
Didatticamente se ne vide la necessità per rendere fluido il passaggio dal registro medio grave verso quello acuto, mentre esteticamente se ne vide la necessità agli inizi dell’800, quando gli organici orchestrali per esigenze compositive iniziavano ad aumentare, e con essi il volume sonoro (dB) e la banda frequenziale (Hz).
Ecco quindi la necessità di creare una nuova modalità di emissione vocale che potesse competere con il nuovo suono orchestrale, che spesso copriva letteralmente l’intensità del suono-vocale.
Questa concentrazione, ovvero l’aumento di volume di questa banda/formante conduce:
- alla caratterizzazione della vocalità lirica (assieme ad altri fattori)
- all’aumento della portanza, la voce corre più lontano
- emesso contemporaneamente ad altri strumenti acustici, il suono vocale risulterà ben evidente
Sia chiaro, è molto riduttivo alquanto apparentemente banale mettere in atto queste azioni: piango, abbasso la laringe, alzo il velo palatino, abbasso la base della lingua, …
Tutto fa sempre parte di un meccanismo, di un equilibrio tra varie componenti, del rapporto tra diversi e simultanei atteggiamenti fisici e mentali – teoria dell’uovo.
Distinzione tra voce maschile e femminile ?
No, pensiamo all’estensione vocale in senso totale ovvero dell’essere umano.
I bassi, baritoni, tenori e contralti risultano essere più timbrati rispetto alle voci femminili acute; da ciò si può dedurre come analizzando il suono vocale di una soprano la formante alta di canto (o rinforzo formantico, o extra formante) sia di bassa intensità, se non del tutto assente.
La sensazione di suono brillante (che non è sinonimo di timbrato) tipico dei soprani è infatti determinato più che dalla scarsa rilevanza della formante alta di canto quanto dalla maggiore intensità rispetto alle altre voci delle prime componenti armoniche.
In alcuni casi il 1° armonico coincide con il 1° formante, data la sua elevata intensità.

Questa sensazione di brillantezza sopranile si ottiene aumentando negli acuti l’apertura della bocca; è infatti ormai assodato come lo sviluppo d’intensità della 1° formante F1 sia in relazione con l’abbassamento del mascellare inferiore.
Quindi si evince che:
- nelle voci maschili o di contralto noi avvertiamo soprattutto l’intensità della formante alta di canto
- nelle voci femminili acute avvertiamo la frequenza fondamentale F0 potenziata dalla sovrapposizione della prima formante.
[/tab]
[/tabs]
[widgets_on_pages id=2]
